IT之家 6 月 11 日消息,科技媒体 marktechpost 昨日(6 月 10 日)发布博文,报道称 Meta 公司推出 LlamaRL 框架,采用全异步分布式设计,在 405B 参数模型上,LlamaRL 将强化学习步骤时间从 635.8 秒缩短至 59.5 秒,速度提升 10.7 倍。
IT之家注:强化学习(Reinforcement Learning,RL)通过基于反馈调整输出,让模型更贴合用户需求。随着对模型精准性和规则适配性的要求不断提高,强化学习在训练后阶段的重要性日益凸显,持续优化模型性能,成为许多先进大语言模型系统的关键组成部分。
将强化学习应用于大语言模型,最大障碍在于资源需求。训练涉及海量计算和多组件协调,如策略模型、奖励评分器等。模型参数高达数百亿,内存使用、数据通信延迟和 GPU 闲置等问题困扰着工程师。
Meta 推出的 LlamaRL 框架,采用 PyTorch 构建全异步分布式系统,简化协调并支持模块化定制。通过独立执行器并行处理生成、训练和奖励模型,LlamaRL 大幅减少等待时间,提升效率。
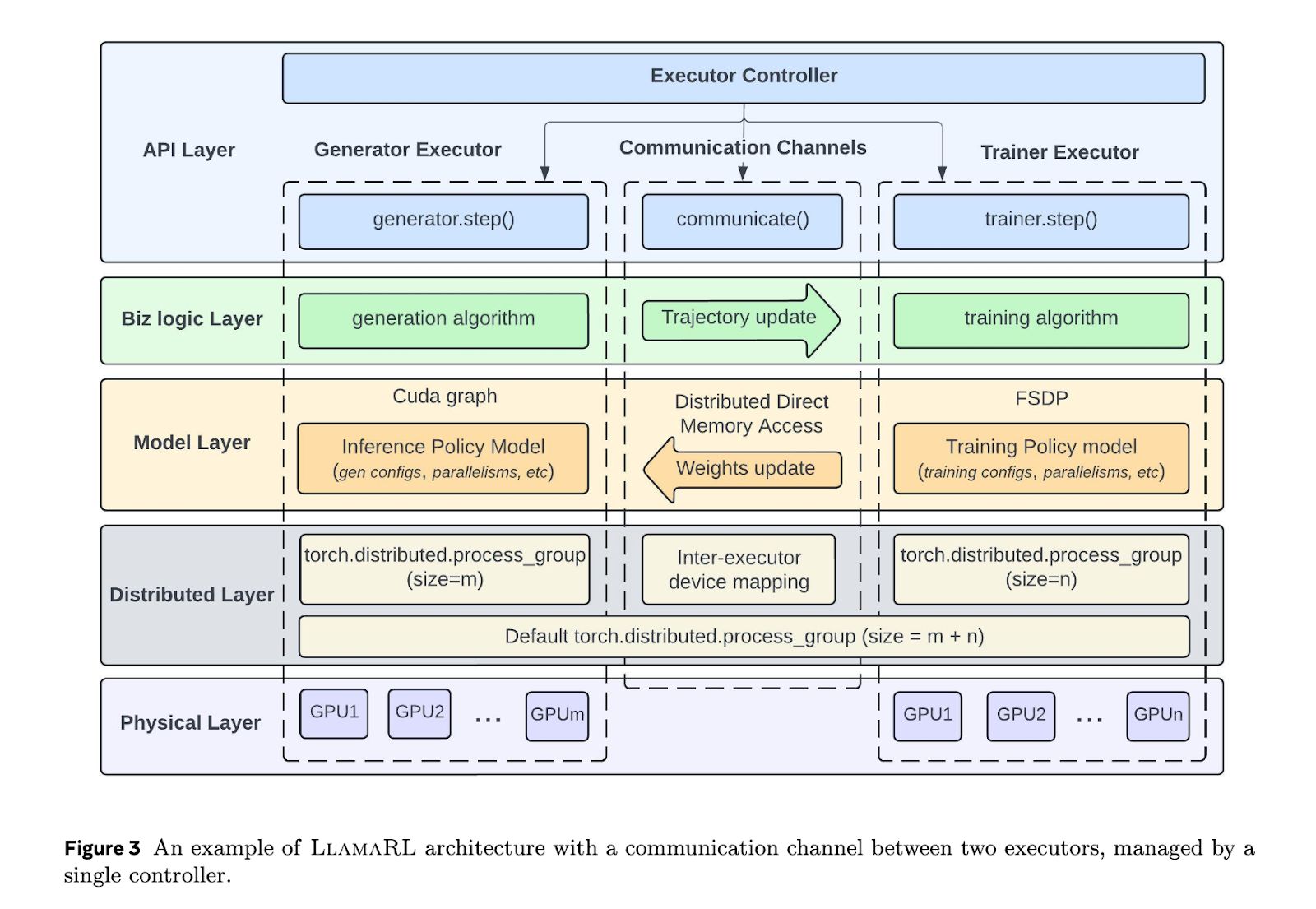
LlamaRL 通过分布式直接内存访问(DDMA)和 NVIDIA NVLink 技术,实现 405B 参数模型权重同步仅需 2 秒。
在实际测试中,LlamaRL 在 8B、70B 和 405B 模型上分别将训练时间缩短至 8.90 秒、20.67 秒和 59.5 秒,速度提升最高达 10.7 倍。
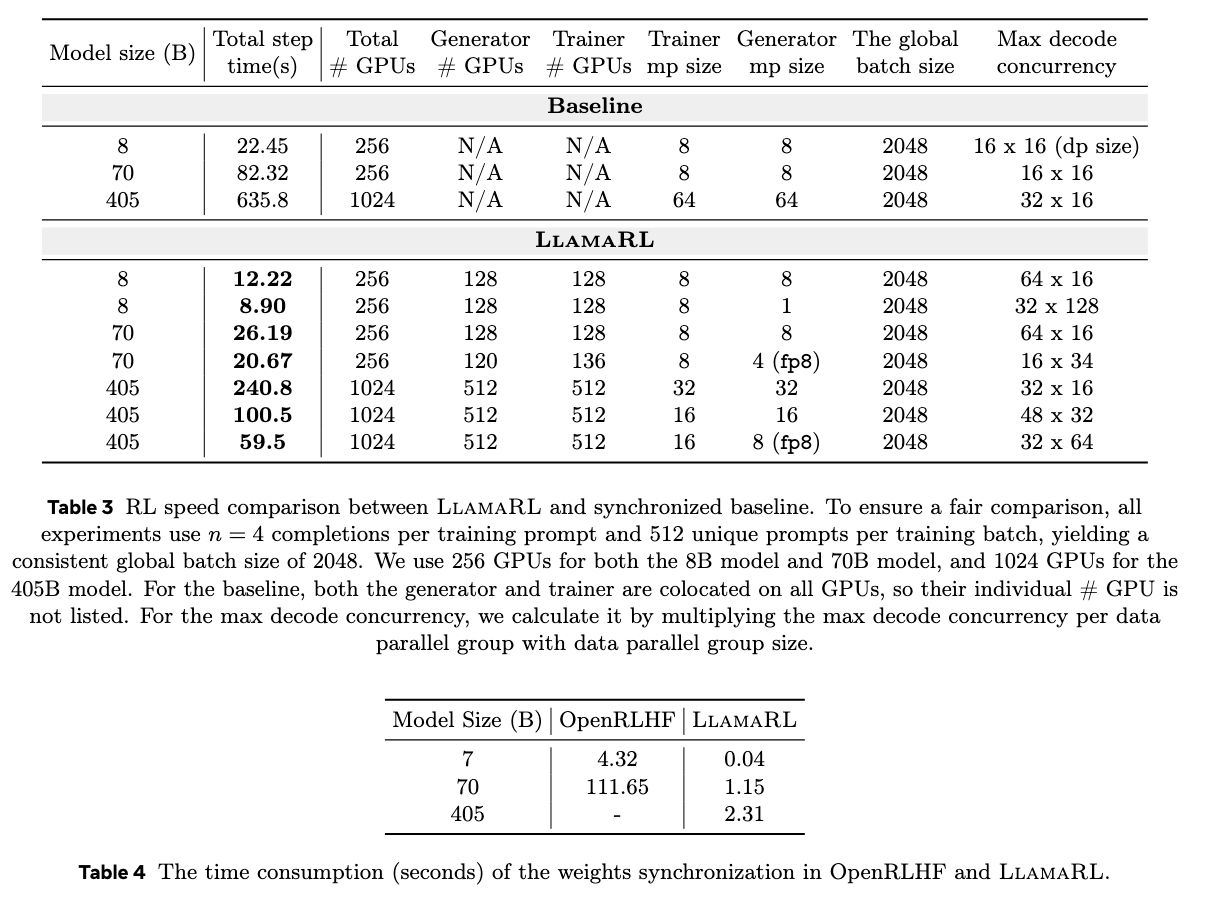
MATH 和 GSM8K 基准测试显示,其性能稳定甚至略有提升。LlamaRL 有效解决内存限制和 GPU 效率问题,为训练大语言模型开辟了可扩展路径。
本网通过AI自动登载内容,本文转载自MSN,【提供者:IT之家 | 作者:佚名】,仅代表原作者个人观点。本站旨在传播优质文章,无商业用途。如不想在本站展示可联系删除。