IT之家 5 月 29 日消息,科技媒体 marktechpost 昨日(5 月 28 日)发布博文,报道称 Meta 公司联合推出 Multi-SpatialMLLM 模型,整合深度感知、视觉对应和动态感知三大组件,突破单帧图像分析的局限。
多模态大语言模型(MLLMs)近年来在视觉任务处理上取得显著进展,但其作为独立数字实体的应用方式限制了实际影响力。
随着机器人和自动驾驶等领域的需求增长,MLLMs 需要具备复杂空间理解能力。然而,现有模型在基础空间推理任务中频频失误,例如无法准确区分左右。
过去的研究将问题归因于缺乏专门训练数据,并尝试通过单张图像的空间数据训练改进,但这种方法局限于静态视角分析,缺乏动态信息处理能力。
Meta 旗下的 FAIR 团队联合香港中文大学,为解决空间理解难题,推出 MultiSPA 数据集,涵盖超过 2700 万样本,涉及多样化的 3D 和 4D 场景。
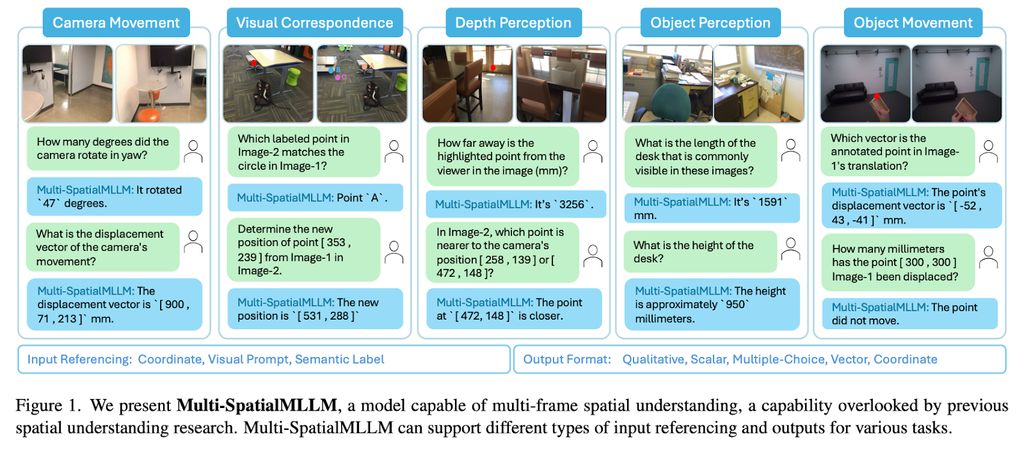
该数据集结合了 Aria Digital Twin、Panoptic Studio 等高质量标注场景数据,并通过 GPT-4o 生成多样化任务模板。
研究还设计了五个训练任务,包括深度感知、相机移动感知和物体大小感知等,提升 Multi-SpatialMLLM 模型在多帧空间推理上的能力。

在 MultiSPA 基准测试中,Multi-SpatialMLLM 相比基础模型平均提升 36%,在定性任务上的准确率达到 80-90%,远超基础模型的 50%,甚至在预测相机移动向量等高难度任务上也取得 18% 的准确率。
在 BLINK 基准测试中,该模型准确率接近 90%,平均提升 26.4%,超越多个专有系统。此外,模型在标准视觉问答(VQA)测试中保持原有性能,显示出不依赖过度拟合空间推理任务的通用能力。
IT之家附上参考地址
本网通过AI自动登载内容,本文转载自MSN,【提供者:IT之家 | 作者:佚名】,仅代表原作者个人观点。本站旨在传播优质文章,无商业用途。如不想在本站展示可联系删除。